
VLLM — это высокопроизводительный, экономичный с точки зрения памяти механизм логического вывода для больших языковых моделей, обеспечивающий более быструю реакцию и эффективное управление памятью. Он поддерживает многоузловые конфигурации для масштабируемости и предлагает надежную документацию для плавной интеграции в рабочие процессы.
Vllm
Платформы: Магистр права
Что такое Vllm? VLLM — это высокопроизводительный, экономичный с точки зрения памяти механизм логического вывода, разработанный специально для больших языковых моделей (LLM). Он оптимизирует процесс обслуживания LLM за счет эффективного управления использованием памяти, ускоряя отклики при сохранении целостности производительности. Инструмент поддерживает различные среды развертывания, что делает его адаптируемым для различных групп пользователей, от небольших стартапов до крупных предприятий. В частности, VLLM позволяет создавать многоузловые конфигурации, повышая масштабируемость и управление нагрузкой во время пиковых запросов.
Основные функции
✅ Основные функции и преимущества Vllm Vllm предлагает множество функций и преимуществ, которые делают его лучшим выбором для различных пользователей. Вот некоторые из ключевых функций: ✔️ Автоматизация любого рабочего процесса. ✔️ Размещение пакетов и управление ими. ✔️ Поиск и устранение уязвимостей. ✔✅ Мгновенная среда разработки. ✔️ Пишите лучший код с помощью искусственного интеллекта.
Примеры использования
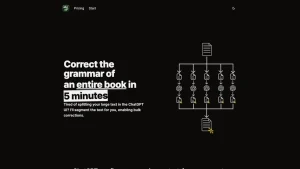
➡️ Примеры использования и приложения Vllm Эффективно развертывают большую языковую модель в облачной среде, используя VLLM для работы с приложениями с высоким трафиком, сохраняя при этом низкую задержку и высокую пропускную способность. Используйте многоузловые возможности VLLM для масштабирования развертываний LLM на нескольких серверах, обеспечивая оптимальную производительность приложений корпоративного уровня в периоды максимальной загрузки. Легко интегрируйте VLLM в существующие рабочие процессы искусственного интеллекта, используя его всеобъемлющую документацию и поддержку сообщества для улучшения вывода больших языковых моделей без обширных знаний в области программирования или технических знаний.


{kind=link}
{kind=link}
{kind=link}